
Reids 是什么
Redis 是一个开源(BSD许可)的,内存中的key-value数据结构存储系统,也是现在最受欢迎的 NoSQL 数据库之一。它可以用作数据库、缓存和消息中间件。
Redis内部提供五种数据类型:String,Hash,List,Set及Zset(sorted set)。详情请访问Redis官网。
Redis 快到什么程度
首先我们通过 Redis 自带的 redis-benchmark 工具来进行下压力测试。
[root@Cube007 ~]# redis-benchmark -n 100000 -q
PING_INLINE: 73529.41 requests per second
PING_BULK: 76103.50 requests per second
SET: 74128.98 requests per second
GET: 73746.31 requests per second
INCR: 71326.68 requests per second
LPUSH: 72889.63 requests per second
RPUSH: 73046.02 requests per second
LPOP: 71225.07 requests per second
RPOP: 73099.41 requests per second
SADD: 74404.77 requests per second
HSET: 75244.55 requests per second
SPOP: 79176.56 requests per second
ZADD: 76923.08 requests per second
ZPOPMIN: 79681.27 requests per second
LPUSH (needed to benchmark LRANGE): 76452.60 requests per second
LRANGE_100 (first 100 elements): 34916.20 requests per second
LRANGE_300 (first 300 elements): 14727.54 requests per second
LRANGE_500 (first 450 elements): 11077.88 requests per second
LRANGE_600 (first 600 elements): 8433.12 requests per second
MSET (10 keys): 60790.27 requests per second这边我们使用了10w的请求数量来进行的计算,尽管我这是一个1核2G的小水管,而其常用的 SET、GET 等命令都达到了7W+的 QPS,足以证明Redis的速度了。
Redis 为什么要用单线程
而我们都知道Redis是单线程的,那为什么Redis要用单线程,而不是用多线程来提高吞吐率呢?
原因也很简单,如果要用多线程,那必然会出现多线程编程模式⾯临的共享资源的并发访问控制问题。
很多时候并发控制不是只用一些锁就能解决的,往往需要更加精细巧妙的设计。而多线程在如Redis这样并发量很高,又极为频繁的获取和修改数据的情况下,大部分的时候往往都浪费在等待上。
而且为了解决各种数据一致性和同步的问题,也会让其设计变的极为复杂而已难以维护。
Redis 为什么快
Redis的快主要有三个原因
- 内存存贮机制
- 高效的数据结构(哈希表,跳表等)
- 多路复用机制
内存操作不用多说,肯定是最快的,Redis的数据结构将会在另一个文章讲一下,这次重点看一下Redis的多路复用机制。
I/O多路复用机制
虽然Redis服务端对于命令的处理是单线程的,但是在I/O层面却可以同时面对多个客户端并发的提供服务,这就是通过I/O多路复用机制实现的。
首先来看一个GET请求的简单过程,从开始需要监听客⼾端请求(bind/listen),和客户端建立连接(accept),从socket中读取请求(recv),解析客户端发送请求(parse),根据请求类型读取键值数据(get),最后给客⼾端返回结果,即向socket中写回数据(send)。
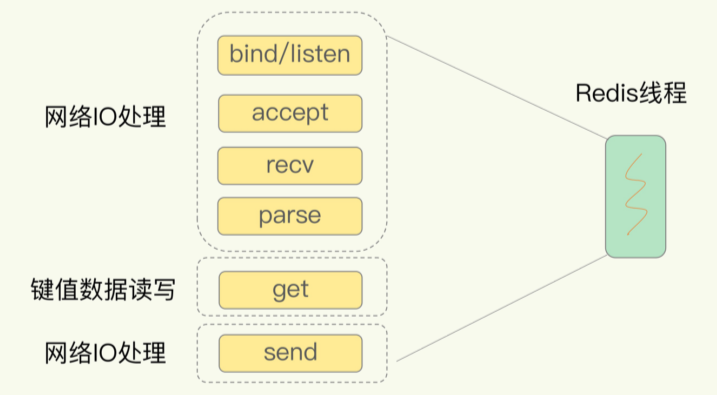
其中和客户端建立连接或者读取请求的时候很容易因为客户端没有相应而阻塞,所以引入了Socket的非阻塞模式。
在socket模型中,不同操作调⽤后会返回不同的套接字类型。socket() 方法会返回主动套接字,然后调用 listen() 方法,将主动套接字转化为监听套接字,此时,可以监听来自客户端的连接请求。最后,调用accept()方法接收到达的客户端连接,并返回已连接套接字。

针对监听套接字,我们可以设置非阻塞模式:当Redis调用accept()但⼀直未有连接请求到达时,Redis线程可以返回处理其他操作,而不用⼀直等待。但是,你要注意的是,调用accept()时,已经存在监听套接字了。
类似的,我们也可以针对已连接套接字设置非阻塞模式:Redis调用recv()后,如果已连接套接字上一直没有数据到达,Redis线程同样可以返回处理其他操作。我们也需要有机制继续监听该已连接套接字,并在有数据达到时通知Redis。
这样才能保证Redis线程,既不会像基本IO模型中⼀直在阻塞点等待,也不会导致Redis⽆法处理实际到达的连接请求或数据。
Linux 中的 epoll 多路复用技术
Redis 非阻塞IO内部实现采用 Liunx 的 epoll 多路复用技术,一个线程可以对多个 IO 端口进行监听,当有读写事件产生时会分发到具体的线程进行处理。过程如下所示:
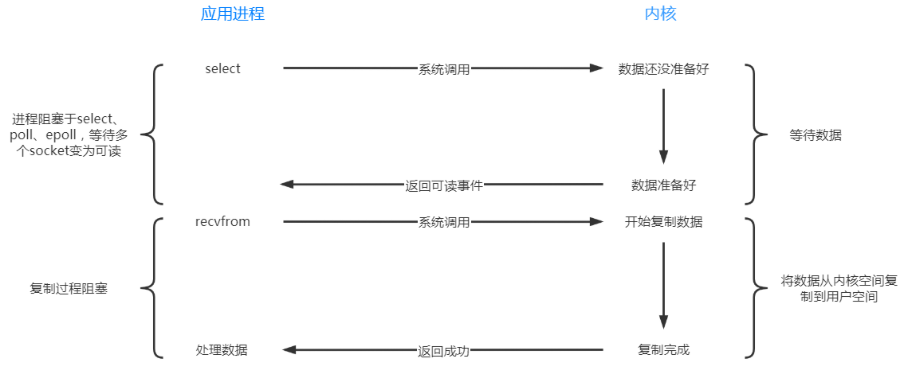
在Redis只运行单线程的情况下,该机制允许内核中,同时存在多个监听套接字和已连接套接字。内核会一直监听这些套接字上的连接请求或数据请求。⼀旦有请求到达,就会交给Redis线程处理,这就实现了⼀个Redis线程处理多个IO流的效果。
这就像病人去医院瞧病。在医⽣实际诊断前,每个病⼈(等同于请求)都需要先分诊、测体温、登记等。如果这些工作都由医生来完成,医生的工作效率就会很低。所以,医院都设置了分诊台,分诊台会⼀直处理这些诊断前的⼯作(类似于Linux内核监听请求),然后再转交给医生做实际诊断。这样即使⼀个医生(相当于Redis单线程),效率也能提升。

文章评论
Cube007棒棒棒