简介
HBase,全名Hadoop DataBase,是一个开源的、分布式的、版本化的非关系型数据库,这意味着它不像传统的关系数据库那样支持SQL作为查询语言。
Hbase是一种分布式存储的数据库,技术上来讲,它更像是分布式存储而不是分布式数据库,它缺少很多关系数据库系统的特性,比如列类型,辅助索引,触发器,和高级查询语言等待。
官网:Apache HBase – Apache HBase™ Home
特点
列式存储
Hbase 是根据列族来存储数据的。将表记录存储在一系列列中,即列中的条目存储在磁盘上的连续位置。列族下面可以有非常多的列。列式存储的最大好处就是,其数据在表中是按照某列存储的,这样在查询只需要少数几个字段时,能大大减少读取的数据量。
稀疏性
在 HBase 的列族中,可以指定任意多的列,为空的列不占用存储空间,表可以设计得非常稀疏。
海量存储
HBase 作为一个开源的分布式 Key-Value 数据库,其主要作用是面向 PB 级别数据的实时入库和快速随机访问。
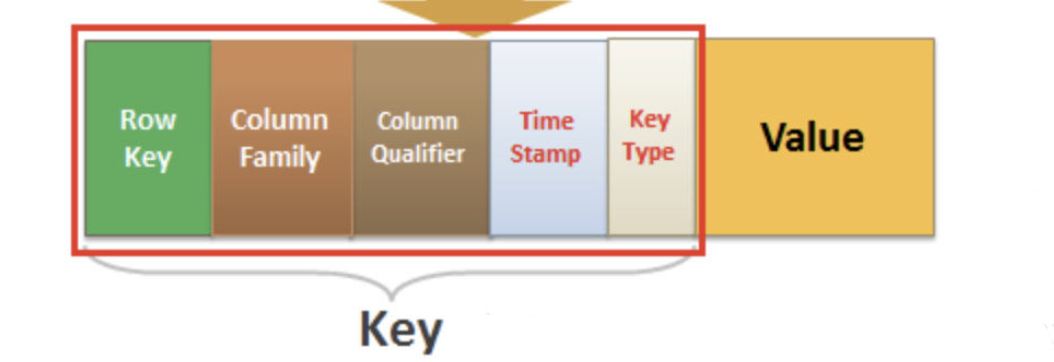
数据模型
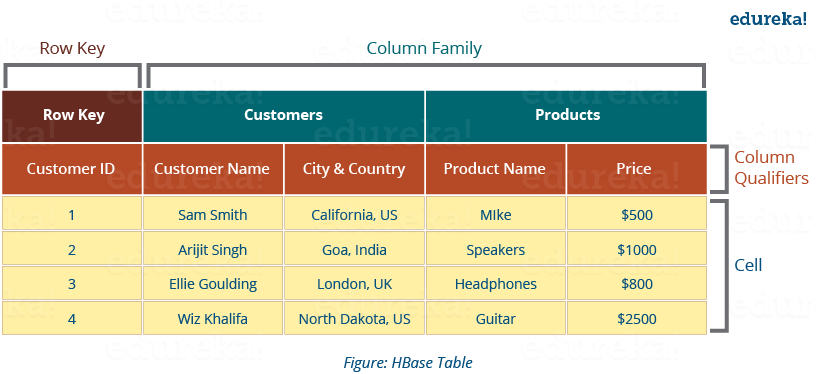
- RowKey:RowKey的概念与关系型数据库中的主键相似,HBase 使用 RowKey 来唯一标识某行的数据。
- Column Family:列族,HBase 基于列划分数据的物理存储。一个列族可以包含包意多列,一般同一类的列会放在一个列族中。
- Column Qualifiers:列限定符,每列的名称
- Cell:数据存储在单元格中。数据被转储到由行键和列限定符专门标识的单元格中。
- TimeStamp:时间戳,能允许Cell存储多个版本值,版本之间通过时间戳来区分。配置 TTL 能使其到期自动删除。
HBase 可伸缩架构
HBase 的核心架构由五部分组成,分别是 HBase Client、HMaster、Region Server、ZooKeeper 以及 HDFS。它的架构组成如下图所示。
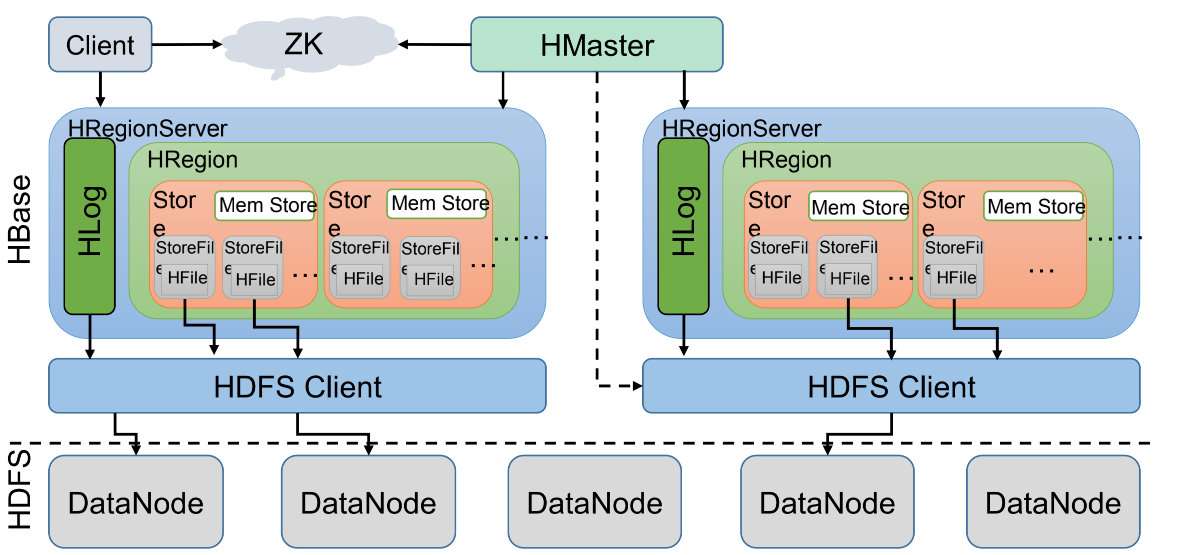
HBase Client
HBase Client 为用户提供了访问 HBase 的接口,可以通过元数据表来定位到目标数据的 RegionServer,另外 HBase Client 还维护了对应的 cache 来加速 Hbase 的访问,比如缓存元数据的信息。
Zookeeper
HBase 通过 Zookeeper 来做 master 的高可用、Region Server 的监控、HMaster 的选举、元数据的入口以及集群配置的维护工作。
HMaster
HMaster 是 HBase 集群的主节点,负责整个集群的管理工作,主要有:
- 协调和管理 Region Server。
- 执行 DDL 操作(创建和删除表)并将区域分配给区域服务器。
- 它监视集群中所有 Region Server 的实例(在 Zookeeper 的帮助下),并在任何 Region Server 关闭时执行恢复活动。
HRegion
HRegion 是 HBase 负责数据存储的主要进程,应用程序对数据的读写操作都是通过和 HRegion 通信完成。数据以 HRegion 为单位进行管理,也就是说应用程序如果想要访问一个数据,必须先找到 HRegion,然后将数据读写操作提交给 HRegion,由 HRegion 完成存储层面的数据操作。而 store 存储的就是一个列族的数据。
HRegionServer
HRegionServer 是物理服务器,每个 HRegionServer 上可以启动多个 HRegion 实例。当一个 HRegion 中写入的数据太多,达到配置的阈值时,一个 HRegion 会分裂成两个 HRegion,并将 HRegion 在整个集群中进行迁移,以使 HRegionServer 的负载均衡。
HLog
我们写数据的时候是先写到内存的,为了防止机器宕机,内存的数据没刷到磁盘中就挂了。我们在写Mem Store的时候还会写一份HLog。
HBase 的应用场景
- 对象存储:头条类、新闻类的的新闻、网页、图片存储在 HBase 之中,一些病毒公司病毒库也是存储在 HBase 之中。
- 风控画像:基于 HBase 的数据结构,尤其是字段数据量比较大,又比较稀疏的矩阵适合储存在 HBase 之中。
- 时空数据:主要是轨迹、气象网格之类,比如滴滴打车的轨迹数据主要存在 HBase 之中。
- CubeDB OLAP:Kylin一个cube分析工具,底层的数据就是存储在HBase之中,不少客户自己基于离线计算构建cube存储在hbase之中,满足在线报表查询的需求。
- Feed流:类似于朋友圈,微博这种应用。

文章评论
好哇!